What If Multi-Agent AI Could Search Three Million PDFs Before Breakfast?
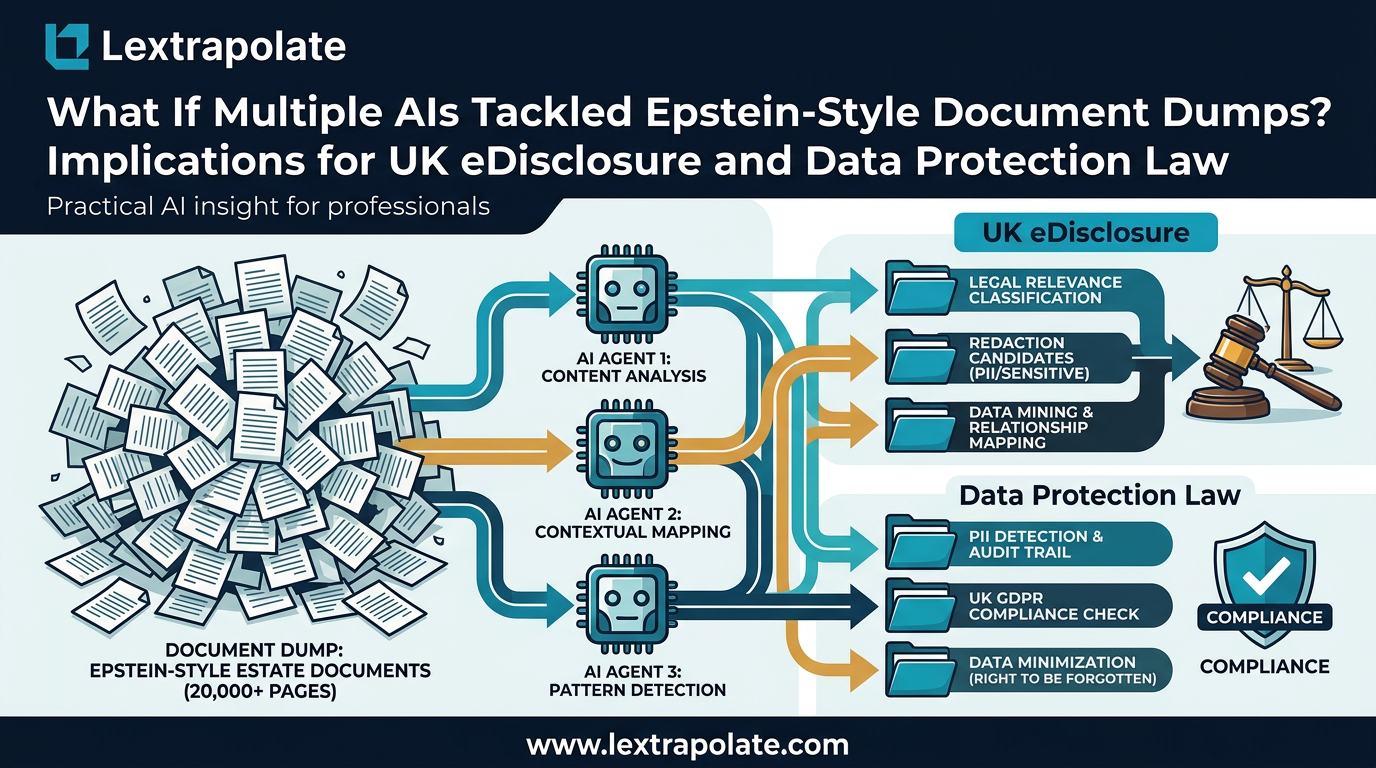
Searching 3,000,000 PDFs for a single thread of evidence is no longer a thought experiment; it is the benchmark for modern disclosure. When the US Department of Justice released the Epstein estate files, it exposed a critical failure in traditional legal infrastructure that every UK litigator must now reckon with.
A group of researchers and journalists sat in front of a "gross" PDF viewer clicking through garbled email threads trying to follow the conversation. Manually. That image should trouble every litigator who has ever managed a large disclosure exercise. Because the honest answer to "how do we review three million PDFs?" has, until recently, been: slowly, expensively, and with a margin of error nobody wants to admit.
That is changing. And the change is material enough that understanding it is no longer optional for practitioners handling complex litigation or disclosure-heavy work.
The PDF Problem Is Not Going Away
PDF is the lingua franca of legal documents and it is also, technically, a nightmare. Unlike structured data, a PDF is a presentation format. The text may be machine-readable or it may be a flat image. Tables do not behave like tables. Footnotes appear wherever the original designer put them. Scanned documents add another layer: OCR errors that corrupt names, dates, and figures.
For years, e-disclosure platforms addressed this with keyword search and linear review teams. That model works when the document set is manageable and the budget is open-ended. Neither condition holds as reliably as it once did.
The modern answer is AI-assisted document analysis: tools that extract, classify, summarise, and score documents at scale. Platforms like Anara, Sopact Sense, and others now apply NLP and machine learning to large PDF sets, pulling out entities, flagging relevance, and generating audit trails that record what the AI found and why. The claimed efficiency gains are significant. Vendors routinely cite time reductions of seventy to ninety percent on review tasks. Those figures deserve scepticism until independently tested, but directionally they reflect something real: AI does not get tired on document forty thousand.
What has shifted recently is the architecture. Single-model AI review is giving way to multi-agent systems. Instead of one model reading every document sequentially, a co-ordinated network of agents divides the work: one agent parses structure, another extracts named entities, another cross-references timelines, another flags privilege. The outputs are then synthesised. This is not just faster. It is structurally different. It can hold more context across a larger document set than any single model with a fixed context window. For a disclosure exercise running to millions of pages, that distinction matters enormously.
What This Means Under CPR Part 31
Disclosure in English civil litigation is governed by CPR Part 31 and, for complex cases, by the Disclosure Pilot under Practice Direction 51U (now substantially incorporated into the rules following the pilot). The duty is to search for documents in a reasonable and proportionate manner. The question of what "reasonable" means has always been partly a question of what technology makes possible.
That question is now being answered differently.
If multi-agent AI can search a million-page document set with greater accuracy and lower cost than a human review team, it becomes harder to justify not using it. The proportionality calculus shifts. Judges applying the overriding objective in CPR 1.1 would, in time, likely expect parties with access to such tools to use them. Failure to do so could attract criticism on costs, if not something stronger.
But the reverse problem is equally real. AI-assisted review does not eliminate the solicitor's duty; it relocates it. The obligation to make proper disclosure does not transfer to the software. The supervising solicitor must understand what the AI did, what parameters it used, whether it was configured appropriately for the document set in question, and whether its outputs have been properly checked. An AI tool that classifies two hundred thousand documents as irrelevant is only as trustworthy as the human who set it up and validated its outputs.
Auditability is therefore non-negotiable. Any AI document review tool used in litigation must produce a transparent record of its methodology. Without that, the court cannot assess the adequacy of the disclosure exercise and opposing counsel cannot meaningfully challenge it.
The Data Protection Overlay
Large disclosure exercises frequently involve personal data. Emails contain names, medical references, financial details, and sometimes special category data within the meaning of Article 9 of UK GDPR. Running that data through an AI document analysis system is processing. It requires a lawful basis. It requires, in most cases, a Data Protection Impact Assessment under Article 35 of UK GDPR, given the scale and nature of the processing.
This is not a theoretical concern. A firm that ingests millions of documents into a third-party AI platform without assessing the data flows, the processor agreements, and the adequacy of the recipient jurisdiction is taking a real compliance risk. The ICO's guidance on automated processing is clear enough: scale does not reduce the obligation, it increases it.
The practical implication is that technology procurement and data protection review must happen before the document review begins, not after. That means involving the firm's data protection officer or external DPO counsel at the scoping stage. It means reviewing the AI vendor's sub-processor list. It means understanding whether data leaves the jurisdiction and, if so, on what basis.
None of this is insurmountable. But it requires forethought, not retrofitting.
What to Do on Monday Morning
If you are managing a disclosure-heavy matter now, or likely to be in the next twelve months, there are concrete steps worth taking before the volume lands on your desk.
First, audit your current review process. Know what your e-disclosure platform can actually do with AI-assisted classification and whether that capability is switched on. Many firms pay for platforms with AI features they never configure.
Second, understand the multi-agent tools that are entering the market. You do not need to become an engineer. You do need to understand what questions to ask a vendor: How does the system handle scanned PDFs with poor OCR? What is the false-negative rate on privilege classification? What does the audit trail look like? Can you export it in a form the court can assess?
Third, brief your data protection team now. The DPIA for AI-assisted document review is not something to draft under time pressure during a live disclosure exercise. Get a template in place. Know your lawful basis. Have your processor agreements reviewed.
Fourth, consider proportionality arguments proactively. If the other side proposes a manual review of a document set that AI could handle more accurately at lower cost, you now have grounds to engage with that. Proportionality runs both ways.
The Epstein files are an extreme case. Three million PDFs released to the public with no search infrastructure is not a disclosure exercise any solicitor will face. But the underlying problem, too many documents and too little time, is one that most litigators recognise. The tools to address it are here. The question is whether practitioners are ready to use them properly.
Being ready properly means understanding the technology, the rules, and the obligations. In that order.
Sources
Stay ahead of the curve
Get practical AI insights for lawyers delivered to your inbox. No spam, no fluff, just the developments that matter.
Chris Jeyes
Barrister & Leading Junior
Founder of Lextrapolate. 20+ years at the Bar. Legal 500 Leading Junior. Helping lawyers and legal businesses use AI effectively, safely and compliantly.
Get in TouchMore from Lextrapolate
AI Citation Hallucinations in Legal Research: The Verification Problem Nobody Has Solved Yet
Fake citations are slipping past peer review at AI conferences. If that's happening in academia, what's the risk in legal practice?
What If AI Agents Became Team Members? UK Legal Risks in AI-Native Operations
AI-native companies are treating autonomous agents like colleagues. UK law firms watching this shift need to understand what it means before they follow suit.
When Your Phone Becomes a Research Assistant: The Legal Questions Multi-Agent AI Raises
AI agents embedded at OS level change how professionals research on the move. The concept is significant. The legal questions it raises are more significant still.