Three Million PDFs and a Broken Viewer: What Mass Document Dumps Mean for AI-Assisted Discovery
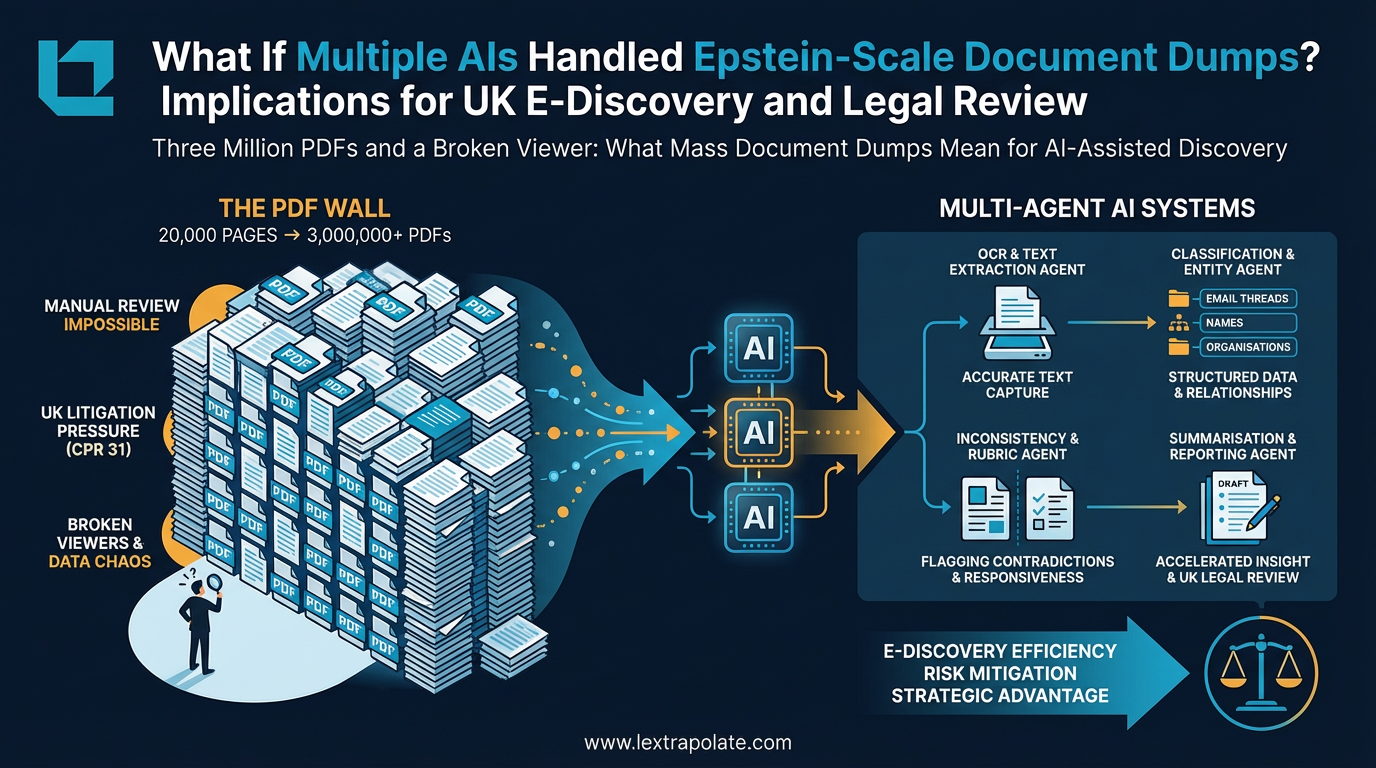
In November 2023, researchers faced a 20,000-page document dump with a failing viewer; by the time the DOJ finished the Epstein file release, the total exceeded 3,000,000 PDFs. For UK litigators governed by CPR 31 and the Disclosure Pilot, this 'PDF Wall' represents a shift where manual review is no longer just slow—it is professionally impossible.
Nobody was going to read those manually. Not properly. Not in any timeframe that mattered.
That scenario is not exotic. It is becoming ordinary.
The PDF Problem Has Not Gone Away
Lawyers have complained about PDFs for twenty years. The format was built for printing, not for analysis. Scanned documents lose structure. OCR introduces errors. Metadata is stripped or buried. Threading across email chains breaks. None of this is new, and yet PDF remains the default format for disclosed materials, court bundles, regulatory productions, and freedom of information releases alike.
Scale is what has changed. Regulators produce more material. Litigation datasets have grown. A single Serious Fraud Office investigation can generate millions of documents. A Competition and Markets Authority inquiry can run to hundreds of thousands of pages of submissions, internal emails, and supporting exhibits. The assumption that a review team can read its way through this in time to run a case is no longer credible.
Technology-assisted review has been part of the UK e-disclosure toolkit for some years. Predictive coding received judicial endorsement in Pyrrho Investments Ltd v MWB Property Ltd [2016] EWHC 256 (Ch), and the concept has been accepted in practice ever since. But predictive coding is essentially a ranking and prioritisation tool. It helps you find what matters faster. It does not read the documents for you, extract relationships, or draft a summary of what it found.
That gap is where a new generation of AI tools is now operating.
What Multi-Agent Systems Actually Do
The phrase "multi-agent AI" is used loosely. In the context of document review, it generally means a pipeline of specialised AI components working in sequence or in parallel: one model handling OCR and text extraction, another performing classification, another identifying named entities and relationships, another flagging inconsistencies or responsive passages against a defined rubric, and another drafting summaries or generating reports.
The advantage of this architecture over a single model doing everything is not merely speed. It is that each component can be tuned for its specific task. An extraction layer can be optimised for scanned PDFs with degraded text. A classification layer can be trained on your specific document types. A relationship-mapping layer can track how names and entities connect across thousands of separate files. No individual model needs to hold the entire context simultaneously.
Vendors including Relativity, Anara, and others in the e-discovery market are building in this direction. Relativity's own experts, writing on their blog, note that generative AI review tools are most valuable when applied to specific, bounded questions rather than left to roam across an entire dataset without direction. That is an honest observation. It implies that the practitioner still has to design the review, not merely switch the AI on.
I have not independently tested any of these systems at scale. The vendor claims about processing speed and accuracy warrant sceptical evaluation before a firm commits to any particular tool in high-stakes litigation.
The UK Legal Framework This Has to Fit Into
CPR Part 31 governs disclosure in civil proceedings. The Electronic Documents Questionnaire under Practice Direction 31B asks parties to consider the sources of electronic documents, the format of production, and the approach to review. The Disclosure Pilot Scheme under Practice Direction 51U, which applied in the Business and Property Courts, pushed parties towards earlier and more structured conversations about what disclosure is actually necessary.
None of this prevents AI-assisted review. But it does create obligations that shape how you use it.
The first is proportionality. Under Extended Disclosure, you must justify the model chosen and the cost of running it. An AI pipeline that costs more than the value in dispute is not automatically defensible. The economics of AI-assisted review have to be argued, not assumed.
The second is reliability. If you are producing documents identified by an AI system as responsive, you are responsible for that production. The Civil Evidence Act 1995 governs the admissibility of documents, but admissibility is rarely the real issue. The real issue is whether your review process was reasonable and whether you can explain it if challenged. A black-box AI producing a list of responsive documents, with no audit trail and no way to test the methodology, creates serious professional risk.
The third is GDPR. A document dump of three million files almost certainly contains personal data. Processing it through an AI system, potentially cloud-hosted, requires a lawful basis and a processor agreement. Running Epstein-scale analysis through a third-party AI API without considering your data processing obligations under the UK GDPR is not a compliance posture any solicitor should be comfortable with.
What This Means
If your firm or client is facing a large-scale disclosure exercise, these are the questions worth asking now rather than after the disclosure order lands.
What are your document sources and what formats are they in? If the answer involves millions of PDFs, you need an AI-assisted strategy from the outset. Trying to retro-fit one after manual review has begun wastes time and money.
What audit trail will your AI system produce? You should be able to show the court, if asked, how responsive documents were identified. "The AI said so" is not an answer. The methodology, the training data, the validation steps, and the error rate all need to be documentable.
Where is your data going? Cloud AI processing of client documents requires proper data governance. This is not optional. Check your processor agreements before running a production dataset through any external AI service.
Have you tested the system on a sample? Before committing to a full review using a tool you have not used before, run it against a subset of documents where you already know the answers. Validate the outputs. Understand where it fails.
The Epstein document releases were unusual in their public visibility, but the underlying problem they illustrated, massive PDF datasets that overwhelm manual review, is one that UK litigation teams encounter regularly. Fraud cases, regulatory investigations, commercial disputes with large document populations: this is the daily reality of heavy-end litigation.
The question is not whether AI has a role in managing that volume. It plainly does. The question is whether practitioners are building the skills to deploy it properly, which means understanding its limits as clearly as its capabilities, and designing review processes that can survive scrutiny.
A broken PDF viewer is a minor inconvenience. A disclosed production that cannot be defended in court is not.
Sources
Stay ahead of the curve
Get practical AI insights for lawyers delivered to your inbox. No spam, no fluff, just the developments that matter.
Chris Jeyes
Barrister & Leading Junior
Founder of Lextrapolate. 20+ years at the Bar. Legal 500 Leading Junior. Helping lawyers and legal businesses use AI effectively, safely and compliantly.
Get in TouchMore from Lextrapolate

What If a Deepfake Became Your Evidence? The Verification Problem Professionals Can't Ignore
AI-generated images and video are flooding professional workflows. Newsroom verification techniques offer a practical defence for lawyers and knowledge workers.
What If Multi-Agent AI Could Search Three Million PDFs Before Breakfast?
PDFs are still the dominant friction point in legal discovery. Multi-agent AI is changing that fast. Here is what practitioners need to understand now.

What If AI Transforms Hiring Overnight? UK Legal and Ethical Risks as Automated Interviews Scale
AI avatars are conducting job interviews at scale. UK employers using these tools face real legal exposure they may not have mapped yet.